KotlinのCoroutineについて
今回はCoroutineについてまとめようと思います
Coroutineは並行実行のデザインパターンです。
そして、特定のスレッドに束縛されない中断可能な計算インスタンスです。
非同期処理で用いられますが、Threadよりも軽量で、実行途中で処理を中断・再開することができます。
今まではRxJavaを使っていましたが、Googleが公式に提供しているのでCoroutineが非同期処理の王道になっています。
Coroutineを使うことによって、作成したクラスが残ってしまうことによるメモリリークを考慮する必要がありません。 ThreadやAsyncTaskを使用する場合、作成したクラスからライフサイクルが終了したActivityやViewModel内のメソッドを呼び出されメモリリークを引き起こすリスクがあります。
Coroutine Scope
CoroutineScopeは、Coroutineが実行される範囲です。
Coroutineは通常、CoroutineScopeで起動されます。
これにより、管理されずに失われるCoroutineがなくなり、リソースが無駄になりません。
CoroutineScopeはライフサイクルに関連付けられ、スコープ内のコルーチンの存続期間を設定します。
Scopeがキャンセルされると、そのJobはキャンセルされ、キャンセルが子Jobに伝播します。
Scope内の子ジョブが例外で失敗すると、他の子Jobがキャンセルされ、親Jobがキャンセルされて、例外は呼び出し元に再度スローされます。
CoroutineScopeは、launchまたはasyncを使用して作成したCoroutineをすべて追跡します(launchやasyncは後述します)。
Android では、独自のCoroutineScopeを提供しています。
たとえば、ViewModelには viewModelScope、Lifecycle(Activityなど)には lifecycleScopeがあります。
ただし、ディスパッチャとは異なり、CoroutineScopeでCoroutineは実行されません。
Coroutineは実行するためには次で説明するBuilderが必要です。
Builder
BuilderとはCoroutineScopeを起点にスレッドを起動して、引数で指定されたタスクブロックを実行します。
簡単にいうと、Builderの役割はコルーチンを開始することです。
Builderは3種類あるのでそれぞれみていきましょう!
launch
launch関数でCoroutineを開始でき、コードブロック内に並列に実行する処理を記述できます。 launchは新規コルーチンを開始し、呼び出し元に結果を返しません。
import kotlinx.coroutines.*
fun main() {
GlobalScope.launch {
println("World!")
}
GlobalScope.launch {
println("start")
}
println("end")
}
上記の処理だと"World!"と"start"は並列なのでどちらが先に出力されるかは明確には決まっておらず、順番が変わる可能性はあります。
また、上記の例の GlobalScopeは先ほど軽く触れたCoroutineScopeと呼ばれています。
※GlobalScopeは取扱注意のCoroutineScopeとして定義されています。
基本的には使わないという認識でいた方がいいと思われます。
GlobalScopeはどのJobにもバインドされません。
GlobalScopeはアプリケーションの寿命を通じて動作する最上位のコルーチンを起動するには使用され、途中でキャンセルされません。
GlobalScope で起動されたアクティブなCoroutineは、プロセスをaliveに維持するものではなく、 デーモンスレッドのように機能します。
GlobalScope は、使用すると誤ってメモリリークを発生させてしまう可能性があるため、取り扱いに注意な API です。
launch() 関数でコルーチンを起動すると、Jobのインスタンスが返されます。
Jobは、コルーチンへの参照を保持するため、そのライフサイクルを管理できます。
Jobを使用すると、Jobのステータス(アクティブ、キャンセル、完了)を確認できます。
Coroutineと、そのCoroutineが起動したCoroutineがすべての処理を完了していれば、Jobは完了です。
なお、Coroutineは別の理由(キャンセルや例外による失敗など)で完了することもありますが、その時点でJobは完了したとみなされます。
また、メインの処理とは別スレッドになるので、launchしたスレッドが終わるまで待つということはありません。 スレッドの状態を確認するプロパティがあるので、うまく使って待ってあげる必要があります。
async
asyncはlaunchとの違い、戻り値の型に特に制限が無いため、任意の値を返せます。(Deferred
これは特定の型のインスタンスを後で返すオブジェクトです。
また、キャンセルも行えます。
Deferred に対して、 await を呼び出すことで最終的なデータを受け取ることができます。
import kotlinx.coroutines.*
import kotlin.system.measureTimeMillis
fun main() = runBlocking {
val n = 2
val add = async {
delay(1000L)
n + 1
}
val multi = async {
delay(1000L)
n * 3
}
val amount = add.await() + multi.await()
println(amount) // (2+1と2 *3の合計の9が出力される)
}
runBlocking
runBlockingは自身を実行したスレッドをブロックするBuilderです。
fun main() {
println("start")
runBlocking {
println("coroutine!")
}
println("end") // start、coroutine!、endの順で表示される
}
上記の例をみるとrunBlockingの処理が終わったら後続の処理が行われていることがわかると思います。
また、runBlockingは実行したCoroutineの戻り値を取得することもできます。 先程の例を次のように変更します。
fun main() {
println("start")
val text = runBlocking {
"coroutine!"
}
println(text)
println("end")
}
この場合も先程と同じく、"start", "coroutine!", "end" の順に出力されます。
runBlockingはCoroutineScopeの拡張関数ではないので、起点のCoroutineScopeを必要としません。 GlobalScopeをrunBlockingの定義内に持っているからです。 runBlockingはGlobalScopeを参照します。
最後にrunBlockingは自身を実行したスレッドをブロックするので、非同期という考えから外れてしまうので使うのをオススメしません。
suspend関数
次にsuspend関数についてです。 suspendは中断という意味があるので、suspend関数は中断可能な処理を表します。 中断のイメージは以下の画像です。
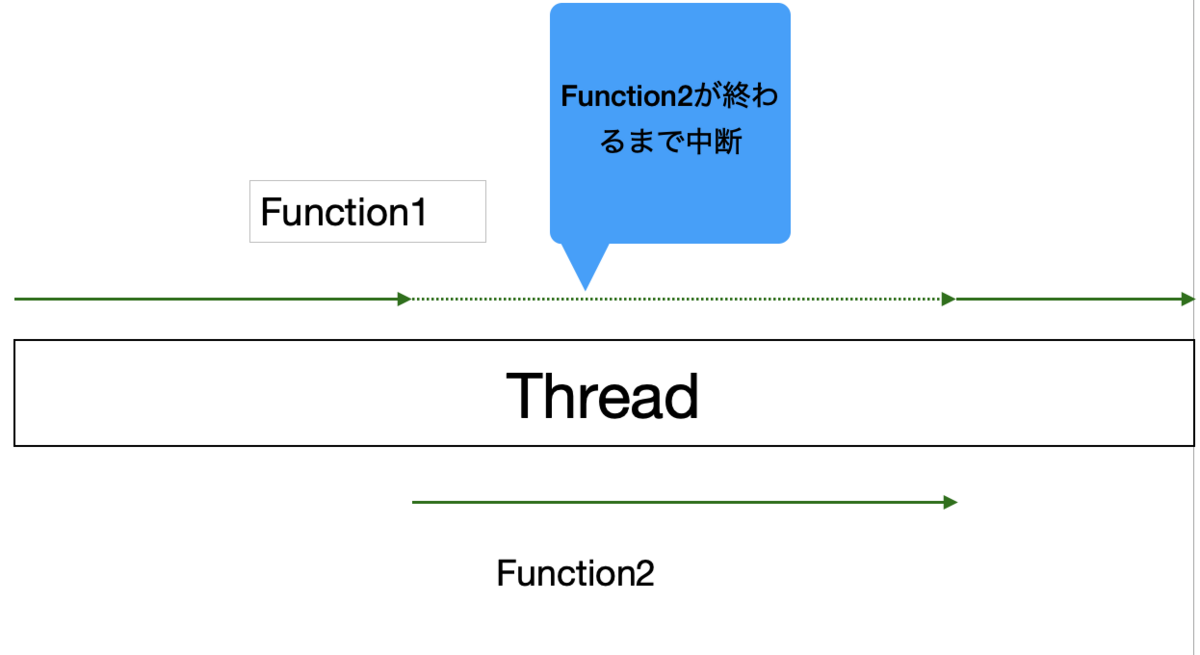
suspend関数は主に以下の特徴があります。
- 暗黙に別のスレッドというのがあり、別のスレッドで行われる(コードには現れない)処理がある
- 呼び出し自体はすぐ返ってくるが実際の処理はこの時点では行われていない
- 実際の処理の終了は、呼び出した関数が終わったあとに、システムからコールバックで返ってくる
- suspendというキーワードのついた関数のbody部にかかれている事は、全部この主スレッドで実行されます。 例えば、launchとかの中で呼び出せばUIスレッドであることを表す
- suspend関数のbody部に書く関数は必ずsuspend関数になる
- Coroutineを開始するには最低1つのsuspend関数がなければなりません
一般的な非同期処理では、呼び出した結果はすぐ戻ってきてしまいます。 呼び出した関数、例えばonCreateの実行はそのまま進んでしまい、サーバーに実際にリクエストがpostされるよりも前に最後まで実行を終えてreturnしてしまいます。 そして、別スレッドの処理が終わると、主スレッドであとからコールバックという関数が呼ばれます。
susupend関数でもほぼメカニズムは同じです。
suspend関数を呼んだ時にはすぐに返ってきて、あとから処理が終わったという通知が主スレッドに何かしらの形でやってきます。
ただ、普通のコールバックとは違ってsuspend関数の結果の呼び出しは直接はコードの上では見えないのが難しく感じる部分かもしれません。
主スレッドで呼び出されたら何か短い処理が走ってすぐ返ってきます。そして、別スレッドに通知がいって、コードには書いてない何かの処理が裏で行われる・
別スレッドの処理が終わると、謎の通知メカニズムで主スレッドにあとから通知が来ます。
これがsuspend関数の実行されるスレッドを考える時の基本になります。
suspend関数のbody部に書く関数は必ずsuspend関数になるに関しては次のようなイメージです
suspend fun getContent(id: Int): String { /* ... */ }
suspend fun getPostContent(id: Int): String {
val content = getContent(id)
return content
}
「Coroutineを開始するには最低 1 つのsuspend関数がなければなりません」について、軽く補足です。
launchの定義は次のようになっています。
public fun launch(
context: CoroutineContext = DefaultDispatcher,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
つまり、先程からlaunchなどでラムダを使用してCoroutineを作成していましたが、実はこれらは無名関数のsuspend関数だったのです。 このように明記されていなけどsuspend関数があるパターンもあります。
Channel
Channelについて説明していきます。
ChannelはメインからもCoroutineからでも使える入れ物のようなものです。
ただ、単なる入れ物ではなく、取り出す(受信する、コンシューマー)スレッドに待ってもらったり、Channelにデータを入れる(送信する、プロデューサー)スレッドにはデータが入っているので送信を待ってもらうなどの交通整理を行います。
そして、Channelは受け取ってもらえるまで送信側の処理が動き続けるので場合によってはメモリリークを引き起こす可能性があるため、注意が必要です。
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.*
fun main() = runBlocking {
val channel = Channel<Int>()
launch {
for (x in 1..5) channel.send(x * x)
}
// receive()は一つずつsendされた情報を受け取る
// なお、ここで中断されるため、sendされない限り次の処理に進まない。非同期でないところに注意
repeat(5) { println(channel.receive()) }
println("Done!")
}
// 出力
// 1
// 4
// 9
// 16
// 25
// Done!
あまり使うイメージがわかない方もいると思いますが、次のようなメリットがあります
- Channelを使用すると、コルーチンが待機することなく、キューに格納されたデータを受信することができます
- Channelは、指定したサイズのバッファを持つことができます。これにより、キューに格納されたデータが多すぎても、コルーチンが待機することなく、プロデューサーが新しいデータを送信することができます
- クローズすることができます。これにより、プロデューサーが新しいデータを送信できなくなったことを、コンシューマーに通知することができます
- プロデューサーとコンシューマーの間で明確な制御ができます。プロデューサーが送信したデータをコンシューマーが受信するまで待機することができ、逆に、コンシューマーが受信するまで、プロデューサーが新しいデータを送信しないように制御することもできます
- 複数のコルーチンで同じChannelにアクセスすることができます。これにより、プロデューサーとコンシューマーが別々のコルーチンで実行される場合でも、データの送受信が可能になります
Flow
Flowは、非同期ストリーム処理を扱うための機能で、Kotlinのコルーチンライブラリに含まれています。
suspend関数は非同期で一つの値を返しますが、Flowは非同期で複数の計算した値を返します。
APIからストリーミングされるリアルタイムデータやデータベースの変更通知など、非同期で取得される複数の値を処理する場合に使用することができます。
Flowは、以下のような特徴があります。
- 再利用可能なコンポーネントとして設計されています。つまり、同じコードを複数の場所で使用することができます。Flowの定義を変更することで、複数の場所で異なる出力を生成することもできます。
- コルーチンがキャンセルされたときに自動的にキャンセルされます。そのため、コードが複雑になることなく、非同期処理をキャンセルすることができます。
- 多様なオペレーターを提供しています。これにより、簡単にフィルタリング、変換、結合、集約などの処理を行うことができます。
- FlowはChannelと違い、受信する処理(collectメソッド)が実行されないと、送信処理(emitメソッド)を行いません。(ColdなObservable/ Stream)そのため、メモリーリークは発生しません。
import kotlinx.coroutines.*
import kotlinx.coroutines.flow.*
fun main() = runBlocking {
launch {
for (k in 1..3) {
delay(500)
}
}
simpleFlow().collect { value -> print(value) }
}
fun simpleFlow(): Flow<Int> = flow {
for (i in 1..3) {
// Thread.sleep(500)
delay(500)
emit(i)
}
}
// 出力
// 1
// 2
// 3
emit関数を使用して値がemitされ、collect関数を使用して値を取得・集計します。
Coroutine使用例
APIをViewModelで呼び出す
個人的にもっとも使うパターンがViewModelでAPI実行などの非同期処理を行うパターンです。 ViewModelでAPIの処理を非同期で行い、結果をActivityやFragmentに伝えるという流れです。
そこで、APIの処理をcoroutineで行うパターンです。取得した結果はLiveDataを使って伝搬します。
class TestViewModel(val app: Application): AndroidViewModel(app) {
private val _sample: MutableLiveData<CustomResponse> = MutableLiveData()
val sample: MutableLiveData<CustomResponse> = _sample
fun get() {
viewModelScope.launch {
try {
val request = TestRequest()
val response = request.get()
_sample.postValue(response)
} catch {
}
}
}
}
class TestRequest: CustomResponse {
// ここで本来はAPIを実行、今回はあくまでもサンプル
suspend fun get() {
return CustomResponse
}
}
class TestActivity: AppCompatActivity() {
override fun onCrerate(saveInstanceState: Bundle?) {
viewModel = ViewModelProvider(this)[TestViewModel::class.java]
viewModel.sample.observe(this) { sample ->
// ViewModelからの結果を取得
}
}
}
CoroutineScopeをviewModelScopeで起動します。
APIの実行部分はsuspend関数にしないとエラーが発生します。
また、LiveDataはStateFlowに置き換えることも可能です。
class TestViewModel(val app: Application): AndroidViewModel(app) {
private val _sample = MutableStateFlow(CustomResponse())
val sample: StateFlow<CustomResponse> = _sample
fun get() {
viewModelScope.launch {
try {
val request = TestRequest()
val response = request.get()
_sample.value = response
} catch {
}
}
}
}
class TestRequest: CustomResponse {
suspend fun get() {
return CustomResponse
}
}
class TestActivity: AppCompatActivity() {
override fun onCrerate(saveInstanceState: Bundle?) {
viewModel = ViewModelProvider(this)[TestViewModel::class.java]
lifecycleScope.launch {
viewModel.sample.collect {
}
}
}
}
変更通知を受け取るには collect を使います。 collect は suspend 関数になってるので、 lifecycleScopeで起動します。
そして、MutableStateFlow の場合は必ずコンストラクタに初期値にパラメータが必要になります。 そのため collect したタイミングで初期値が必ず通知されることになります。 これはコンストラクタにnullを設定した場合でも通知されるのがLiveDataと異なるので意識しましょう!
MutableStateFlowはメインスレッド・バックグラウンドスレッド関係なくvalueを設定することで更新します。 StateFlowの場合はCoroutineContextによって値を受け取るときのスレッドを制御することができます。 lifecycleScope はデフォルトではメインスレッドで動くようになっています。 これは制御可能で、次のようにすることで collect の処理を IO Workerで動かすことが可能になります。そのため、UI変更の処理をしてるともちろんクラッシュします。
lifecycleScope.launch(Dispatchers.IO) {
viewModel.stateFlow.collect {
// メインスレッドで実行してないので、UIを変更しようとするとクラッシュする
textView.text = "$it"
}
}
EventBus
coroutinesを使ってEventBusのように使うことができます。
EventBusはEventが発火されたら、そのEventの発火を待ち受けていた別の箇所で処理をする仕組みです。 イベントを発行するオブジェクト(Publisher)と、そのイベントに対する処理を実行するオブジェクト(Subscriber)をつなぐ仕組みを提供します。 EventBusは、PublisherとSubscriberを疎結合にすることで、コードの柔軟性と保守性を向上させることができます。 つまり、PublisherとSubscriberは、EventBusを介して明示的に接続される必要はありません。 また、PublisherとSubscriberが同じスレッド上で実行されている必要もありません。
EventBusをRxJavaで作っていた方が今までは多いと思います。 Courtineで作成する場合には、Channelを使って可能ですが、演算のオペレータがなかったり、closeを忘れるとメモリリークを引き起こす可能性があります。 そこでFlowを使ってEvent Busを実現させます。
まずはイベントを管理するクラスを作成します
class EventFlow {
private val flow = MutableSharedFlow<String>()
suspend fun sendEvent(event: String) = flow.emit(event)
fun subscribe(scope: CoroutineScope, onConsume: (String) -> Unit) {
flow.onEach {
onConsume(it)
}.launchIn(scope)
}
}
今回はホットストリームなFlowとして扱えるSharedFlowを使います。
これにより複数箇所から呼び出してもFlow側の処理数が増えることはありません。
そして、subscribe()の引数で指定したscopeの中で、Flowのイベントを待ち受けます。
class TestActivity : AppCompatActivity() {
private val eventFlow = EventFlow()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
//EventFlowをsubscribeしてイベントを待ち受ける
eventFlow.subscribe(lifecycleScope) {
when (it) {
"BUTTON_PUSHED" -> {
// イベントを受けとったら処理を行う
}
}
}
findViewById<Button>(R.id.button).setOnClickListener {
runBlocking {
//Event発火
eventFlow.sendEvent("BUTTON_PUSHED")
}
}
}
}
上記のようにsendEventでイベントを発火したらsubscribeを定義している箇所で処理を行います。 今回はイベント発火とイベントを受け取るのを同一クラスで行いましたが、別々のクラスでも可能です。
最後に
Coroutineについて紹介しましたが、まだまだ理解が浅い箇所や知らない機能もあります。 しかし、ドキュメントが充実しているので1度確認するのをオススメします!